Overview
Visual perception of the environment is a critical feature for mobile robots, drones, driver assistance systems and other products like autonomous vehicles. Without visual perception, it is in general not possible for machines to perform meaningful interaction with the surrounding environment. Besides the feature set and robustness of visual perception systems, the size, cost, power consumption and real-time capabilities are key factors to enable successful products in this area.
Many key algorithms for visual perception are available today from current computer vision research. However, these algorithms have a high demand for computing power, especially in the context of real-time systems. Because of this, and when using regular computing platforms, the hardware will become expensive, large and will exhibit a high power consumption. This results in severe limitations for potential applications. Many of them will not be feasible because of technical or commercial reasons.
Technology Base
Embedded computer vision systems normally consist of one or more cameras and a processing system interpreting the image data. For most applications, the cameras are rather simple, built from off-the-shelf image sensors and lenses. The processing and interpretation of the image data is the relevant part of such systems.
The demand on computational power for real-time computer vision applications is extremely high. Images have to be processed in real-time with several different algorithms running in parallel. Besides the performance of the algorithms, the computing power and the cost of the processing system are essential for the feasibility of most applications.
In embedded systems the situation is even more demanding. Power consumption and in most cases also the unit price are very critical. A competitive processing system must utilize all technical options to gain maximum processing power at the lowest possible price point and power consumption.
For building a processing system and implementing functionality on it, there are several alternatives available. Between the possible alternatives, there is a trade-off between several factors, the most important are:
Power consumption (performance per Watt)
Part cost (performance per $)
Engineering cost (NRE, time to market)
Considering the effort for the implementation, the most efficient way is to write software and execute it on a processor. GPUs (Graphics Processing Units) can offer a significantly higher performance than processors at the cost of higher development effort. Nevertheless, they do not nearly reach the performance domains of FPGAs and custom developed ASICs, see the following imagefor a schematic overview.
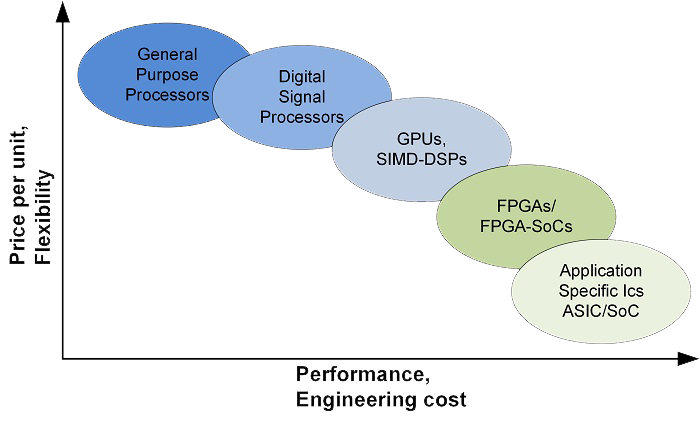
Differences in achievable performance depend, of course, also on the application. Without going into details, it can be said that computationally demanding parts of most computer vision algorithms are perfectly suited for FPGA and ASIC implementation.
Considering the part cost and performance per Watt, FPGAs and especially custom ASICs are by far the best technology for embedded computer vision systems. The performance gain from a GPU to an FPGA can reach a factor of 50, meaning that the performance of a GPU consuming 200 Watts can be achieved by an FPGA consuming less than 4 Watt.
The drawback of implementing algorithms using FPGA and ASIC technology is the significantly higher effort and complexity of such development. However, most computer vision applications can be based on the same algorithms. Once implemented for a generic vision platform, the implemented algorithms can be reused for several applications.
Additionally, modern FPGAs are combined with general-purpose processor cores in a single FPGA-SoC. It is only necessary to implement the performance critical algorithms inside the FPGA logic. The algorithms with a lower demand on computing power can run in software on a processor core. The same principle holds for ASICs and custom SoCs.
Of course, custom ASICs are not reprogrammable in contrast to FPGAs. Therefore, from all programmable architectures to implement computer vision algorithms on them, FPGA are by far the most efficient choice.
Efficient Hardware Design
To achieve maximum performance and efficiency there are several things to consider. Compared to software development, for example on GPUs, the design space and the possibilities for design decisions are much larger.
Accelerating algorithm execution with ASIC and FPGA technology is not only a question of efficient implementation, it starts with the algorithm design itself. Not all algorithms can be efficiently implemented in FPGAs. For a simple example, floating point arithmetic is inefficient on FPGAs, for ASICs this is not necessarily a big deal. Fixed-point implementations tailored for the algorithm in question can significantly reduce the resouce usage.
Another major aspect of efficient accelerator design is the required bandwidth and access pattern to the external memory. For image processing tasks with data sets with the size of images or even 3D or 4D volumes, it is often not possible to keep whole images and derived data inside the internal memory. Of course, trivial algorithms like image filters can linearly access the data.
For more complex algorithms it is often necessary to design dedicated memory sub-systems like caches, prefetch-buffers, etc. Often the main effort of the accelerator development lies in the design of the memory sub-system making it the critical component.
There are several different aspects to consider for efficient accelerator implementation, but the highest levels of performance can only be reached if the algorithms and the architecture are designed together with a deep understanding for both aspects.